
LifeClock (Teil 2/2): Refactoring zu Clean Architecture#
Sechs Monate nach Abschluss meines CS50 LifeClock-Projekts wollte ich Meilensteine zu meinem Poster hinzufügen. Dann wollte ich ein Web-Interface. Dann Themes. Jede Änderung bedeutete, sich durch verworrenen Code zu kämpfen, Tests zu brechen und sich zu fragen: „Warum ist die Geburtstags-Logik mit dem Rendering vermischt?" Das Projekt, das mit 200 Zeilen begann, war schmerzhaft wartbar geworden. Es war Zeit für einen richtigen Rebuild.
LifeClock-Serie: Dies ist Teil 2/2. Falls du es noch nicht gelesen hast, beginne mit Teil 1/2: Von Memento Mori zu Python.
Dies ist der Moment, in dem viele Python-Projekte still zu einem Big Ball of Mud werden: einem fragilen Chaos, wo eine „kleine Änderung" an einer Stelle überraschende Fehler an anderer Stelle auslöst. Dieser Artikel dokumentiert meine Transformation von einem funktionierenden CS50-Script zu einer wartbaren Clean Architecture-Anwendung. Wenn du dich fragst, wann und wie man architektonische Muster auf reale Projekte anwendet, könnte diese Reise helfen.
Was ist Clean Architecture?#
Clean Architecture ist eine Software-Design-Philosophie, die dir hilft, Anwendungen zu bauen, die Bestand haben. Im Kern geht es darum, Code so zu organisieren, dass die wichtigsten Teile—deine Business-Logik—rein und unabhängig von den chaotischen Details von Frameworks, Datenbanken und Benutzeroberflächen bleiben.
Denke daran wie beim Hausbau: Du möchtest, dass das Fundament (deine Kern-Business-Regeln) solide und unabhängig ist. Ob du später entscheidest, die Wände blau zu streichen oder Solarpanele auf dem Dach zu installieren, sollte nicht erfordern, dass du das Fundament abreißt. Clean Architecture gibt dir dieselbe Flexibilität im Code.
Das Problem: Warum Architektur Wichtig Ist#
Die meisten Anwendungen beginnen einfach. Du schreibst ein paar Funktionen, fügst eine Datenbank hinzu, baust ein UI, und alles funktioniert. Aber mit der Zeit passiert etwas Subtiles: Deine Business-Logik wird mit deinem Datenbank-Code vermischt. Dein UI hängt versehentlich von spezifischen Datenbank-Queries ab. Wenn du von SQLite zu PostgreSQL wechseln oder eine Mobile-App neben deiner Web-App hinzufügen möchtest, stellst du fest, dass „einfache Änderungen" das Umschreiben großer Teile deines Codebases erfordern.
Das ist es, was Robert C. Martin einen “Big Ball of Mud” nennt—Code, bei dem alles von allem anderen abhängt. Clean Architecture verhindert dies, indem strikte Grenzen zwischen verschiedenen Anliegen durchgesetzt werden.
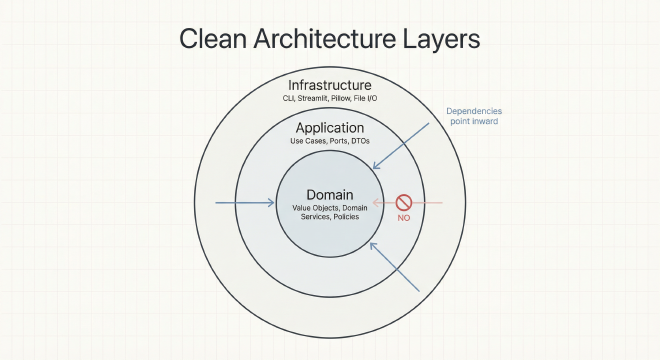
Die Drei Schichten: Eine Klare Trennung#
Die Architektur teilt Code in drei konzentrische Kreise, wie Schichten einer Zwiebel:
graph TB
subgraph infrastructure [Infrastructure Layer]
CLI[CLI Interface]
Streamlit[Streamlit Web UI]
Pillow[Pillow Renderer]
end
subgraph application [Application Layer]
DTOs[DTOs
Pydantic]
UseCases[Use Cases]
Ports[Ports
Interfaces]
end
subgraph domain [Domain Layer]
ValueObjects[Value Objects]
Services[Domain Services]
Policies[Business Policies]
end
CLI -->|erstellt| DTOs
Streamlit -->|erstellt| DTOs
DTOs -->|übergeben an| UseCases
UseCases -->|orchestriert| Services
UseCases -->|definiert| Ports
Pillow -.implementiert.-> Ports
DTOs -.konvertiert zu/von.-> ValueObjects
Services --> Policies
Die Goldene Regel: Abhängigkeiten Zeigen Immer Nach Innen
Dies ist das nicht verhandelbare Prinzip, das die Architektur “clean” macht: Quellcode-Abhängigkeiten dürfen nur nach innen zeigen, zum Zentrum hin. Die äußeren Schichten (Infrastructure) können von inneren Schichten (Application, Domain) importieren, aber innere Schichten dürfen niemals von äußeren Schichten importieren.
Warum ist das wichtig? Weil es bedeutet, dass deine Kern-Business-Logik null Abhängigkeiten von Frameworks, Datenbanken oder UI-Bibliotheken hat. Du kannst sie isoliert testen, Infrastructure-Komponenten frei austauschen und die Business-Regeln verstehen, ohne dich durch technische Details zu wühlen.
Zuordnung zu Robert C. Martins Original-Terminologie
Falls du Martins Buch “Clean Architecture” gelesen hast, hier ist die Zuordnung meiner Implementierung zu seinen kanonischen vier Schichten:
- Entities → Mein Domain Layer (Value Objects, Domain Services, Business Policies)
- Use Cases → Mein Application Layer (Use Case Orchestratoren, Port-Definitionen)
- Interface Adapters → Mein Application Layer (DTOs, Datenkonvertierung) + Infrastructure Adapter
- Frameworks & Drivers → Mein Infrastructure Layer (Pillow, Streamlit, CLI, File I/O)
Lass mich erklären, was jede Schicht tatsächlich in einfachen Worten macht:
1. Domain Layer: Reine Business-Logik
Dies ist das Herz deiner Anwendung—das “Was” und “Warum” deines Business. Im LifeClock weiß der Domain Layer:
- Wie man Lebenserwartung basierend auf Lifestyle-Faktoren berechnet
- Wie man Meilenstein-Daten zu Wochen-Indizes auf dem Grid auflöst
- Wie man validiert, dass ein Geburtsdatum vernünftig ist oder ein Meilenstein nicht in der Zukunft liegt
Was er nicht weiß: irgendetwas über Pillow Image Rendering, Streamlit-Formulare, Command-Line-Argumente oder wie Daten gespeichert werden. Er ist komplett technologie-agnostisch.
2. Application Layer: Orchestrierung & Verträge
Diese Schicht koordiniert Domain-Logik, um spezifische Aufgaben (Use Cases) zu erfüllen, und definiert Verträge (Ports), die äußere Schichten erfüllen müssen. Im LifeClock führt der Application Layer:
- Orchestriert den 10-Schritte-Workflow zur Poster-Generierung
- Konvertiert externe Daten (DTOs) in Domain-Objekte
- Definiert abstrakte Interfaces wie
PosterRenderer, die sagen: “Ich brauche etwas, das ein Poster rendern kann, aber es ist mir egal, ob es Pillow, Cairo oder SVG benutzt”
Denke daran wie an den Dirigenten eines Orchesters: Er weiß, welche Instrumente wann spielen müssen, kümmert sich aber nicht um die spezifische Marke der Geige, die du benutzt.
3. Infrastructure Layer: Die Reale Welt
Hier trifft Gummi auf Straße—alle chaotischen, konkreten Implementierungen. Im LifeClock führt der Infrastructure Layer:
- Benutzt Pillow, um tatsächlich Pixel zu zeichnen und PNG-Dateien zu erstellen
- Baut das Streamlit UI mit Formularen, Buttons und Datei-Downloads
- Parst Command-Line-Argumente mit argparse
- Verwaltet Material Design Icon-Dateien und WCAG-Kontrast-Berechnungen
Diese Komponenten sind Adapter, die die vom Application Layer definierten Verträge implementieren. Möchtest du Pillow gegen einen browser-basierten Canvas-Renderer austauschen? Schreibe einen neuen Adapter, der PosterRenderer implementiert. Die Domain- und Application-Layer merken nicht einmal, dass die Änderung stattgefunden hat.
Das Fundament: SOLID und Dependency Inversion Verstehen#
Bevor wir in die Clean Architecture Schichten eintauchen, müssen wir die fundamentalen Prinzipien verstehen, die sie funktionieren lassen. Clean Architecture basiert auf den SOLID-Prinzipien—fünf Design-Prinzipien, die objektorientiertes Software-Design leiten. Von diesen fünf ist das Dependency Inversion Principle (DIP) der architektonische Grundpfeiler.
Was ist das Dependency Inversion Principle?#
DIP besagt: High-Level-Module (Business-Logik) sollten nicht von Low-Level-Modulen (technische Details) abhängen. Beide sollten von Abstraktionen (Interfaces) abhängen.
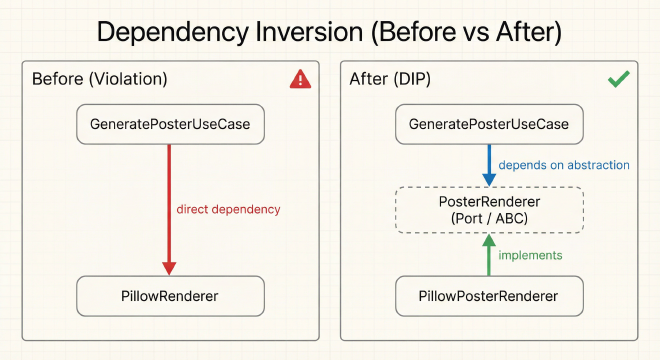
Lass mich dies mit einem konkreten Beispiel aus LifeClock aufschlüsseln:
Vorher (Verletzung von DIP):
from infrastructure.pillow_renderer import PillowRenderer # ❌ Direkte Abhängigkeit
class GeneratePosterUseCase:
def __init__(self):
self.renderer = PillowRenderer() # Application hängt von Infrastructure ab!
def execute(self, profile_data):
# ... Business-Logik ...
return self.renderer.render(stats, milestones)
Dies erscheint harmlos, erzeugt aber ein Tight-Coupling-Problem. Der Use Case (High-Level Business-Logik) importiert und instanziiert direkt eine konkrete Infrastructure-Klasse. Das bedeutet:
- Du kannst den Use Case nicht ohne installiertes Pillow testen
- Der Wechsel zu einem anderen Renderer erfordert das Ändern des Use-Case-Codes
- Der Use Case kennt Implementierungsdetails, die ihn nicht kümmern sollten
Nachher (DIP Befolgung):
from abc import ABC, abstractmethod
# Schritt 1: Definiere eine Abstraktion im APPLICATION Layer
class PosterRenderer(ABC):
"""Abstract Interface, das definiert, was ein Poster Renderer tun muss.
Dieser Vertrag ist im Besitz des Application Layers—nicht Infrastructure.
"""
@abstractmethod
def render(self, *, weeks_total: int, week_index: int,
milestones: list, theme: str) -> bytes:
"""Rendere ein Poster und gebe PNG-Bytes zurück."""
pass
# Schritt 2: Use Case hängt NUR von der Abstraktion ab
class GeneratePosterUseCase:
def __init__(self, renderer: PosterRenderer): # ✅ Hängt von Abstraktion ab
self.renderer = renderer
def execute(self, profile_data):
# ... Business-Logik ...
return self.renderer.render(stats, milestones)
# Schritt 3: Infrastructure implementiert die Abstraktion
class PillowPosterRenderer(PosterRenderer): # Konkrete Implementierung
def render(self, *, weeks_total: int, week_index: int,
milestones: list, theme: str) -> bytes:
# ... Pillow-spezifische Implementierung ...
return png_bytes
Beachte, was passiert ist: Wir haben die Abhängigkeitsrichtung invertiert. Anstatt dass der Use Case von Pillow abhängt, haben wir Pillow vom Vertrag abhängig gemacht, den der Use Case definiert. Der Application Layer besitzt jetzt das PosterRenderer-Interface, und Infrastructure muss sich ihm anpassen.
Warum Abstract Base Classes (ABC) Verwenden?#
Python gibt uns zwei Hauptwege, um Interfaces zu definieren: Abstract Base Classes (ABC) und Protocols. LifeClock verwendet primär ABC für seine Port-Definitionen, und hier ist warum:
Was sind Abstract Base Classes?
Eine ABC ist eine Klasse, die einen Vertrag mit abstrakten Methoden definiert, die Subklassen implementieren müssen. Pythons abc-Modul stellt diese Funktionalität bereit:
from abc import ABC, abstractmethod
class IconManager(ABC):
"""Abstract Port für Icon-Management."""
@abstractmethod
def get_icon_by_key(self, key: str) -> IconDTO:
"""Hole ein spezifisches Icon per Key."""
raise NotImplementedError
@abstractmethod
def get_curated_icons(self) -> list[IconDTO]:
"""Hole alle kuratierten Icons."""
raise NotImplementedError
Vorteile von ABC in LifeClock:
Explizite Verträge: Subklassen müssen explizit von der ABC erben und alle abstrakten Methoden implementieren. Du kannst nicht versehentlich vergessen, eine Methode zu implementieren.
Laufzeit-Validierung: Wenn du versuchst, eine Klasse zu instanziieren, die von einer ABC erbt, aber nicht alle abstrakten Methoden implementiert, wirft Python sofort einen
TypeError.IDE-Unterstützung: IDEs wie PyCharm und VS Code können dich warnen, wenn eine Subklasse das Interface der ABC nicht vollständig implementiert.
Dokumentation: Wenn du
class PillowPosterRenderer(PosterRenderer)siehst, ist sofort klar, dass dies eine Implementierung eines definierten Vertrags ist.
In LifeClock verwende ich ABC für die drei Haupt-Ports:
PosterRenderer: Definiert, wie Poster gerendert werdenIconManager: Definiert, wie Icons verwaltet und abgerufen werdenThemeManager: Definiert, wie Themes und Farbvalidierung gehandhabt werden
ABC vs Protocol: Wann Was Verwenden?
Python 3.8+ führte auch Protocols (strukturelles Subtyping) ein, die keine explizite Vererbung erfordern. Sam Keens “Clean Architecture with Python” diskutiert beide Ansätze. Hier ist der Trade-off:
- Verwende ABC wenn: Du explizite, vererbungsbasierte Verträge mit Laufzeit-Validierung möchtest (was LifeClock tut)
- Verwende Protocol wenn: Du “Duck Typing” mit statischer Typ-Überprüfung möchtest, das existierenden Klassen erlaubt, Interfaces zu erfüllen, ohne Modifikation
Für LifeClock’s Architektur bot ABC die Klarheit und Sicherheit, die ich wollte—wenn ein Adapter einen Port nicht vollständig implementiert, schlägt der Code sofort mit einer klaren Fehlermeldung fehl.
Die Transformation: Vorher und Nachher#
Lass mich dir konkrete Beispiele zeigen, wie das Refactoring die Code-Struktur verändert hat.
Vorher (CS50-Version):
# Alles an einem Ort
def compute_expectancy(baseline, activity, smoking, sleep, height, weight):
delta = 0.0
if activity == "high": delta += 2.0
if smoking == "heavy": delta -= 8.0
# ... gibt direkt eine Zahl zurück
return max(40, min(120, baseline + delta))
Nachher (Clean Architecture):
# Domain Layer: Reine Business-Logik
@dataclass(frozen=True)
class ExpectancyPolicy:
"""Kapselt Lebenserwartungs-Anpassungsregeln."""
def compute_delta(self, activity: str, smoking: str,
sleep_hours: int, bmi: float) -> float:
delta = 0.0
if activity == "high": delta += 2.0
if smoking == "heavy": delta -= 8.0
return delta
# Application Layer: Koordiniert die Logik
def calculate_expectancy_uc(profile_dto: ProfileDTO) -> float:
"""Use Case: Berechne Lebenserwartung."""
policy = ExpectancyPolicy()
profile = profile_dto.to_domain()
return policy.apply(profile)
Warum das wichtig ist: Die Policy kann ohne UI, Datenbank oder Rendering getestet werden. Es ist reine Logik, die überall laufen kann.
Die Dateistruktur-Transformation erzählt dieselbe Geschichte. Was einst zwei Dateien waren (project.py und helpers.py mit insgesamt 300 Zeilen), wurde zu einer klaren Verzeichnishierarchie, die die architektonischen Schichten widerspiegelt: domain/ für reine Business-Logik, application/ für Use Cases und Interfaces, und infrastructure/ für externe Adapter.
Schicht für Schicht: Die Drei Kreise#
Domain Layer: Das Herz#
Der Domain Layer ist, wo deine Business-Logik lebt – die Regeln, die auch existieren würden, wenn du morgen von Python zu einer anderen Sprache wechselst. Entscheidend: Diese Schicht hat null Abhängigkeiten von externen Libraries oder Frameworks – nur Pythons Standardbibliothek.
Value Objects: Die Bausteine
Alle Domain-Objekte verwenden unveränderliche Dataclasses (@dataclass(frozen=True, slots=True)) mit Validierung in __post_init__. Dies garantiert, dass wenn ein Objekt existiert, es valide ist. Die drei Kern-Value-Objects sind:
Profile: Erfasst Benutzer-Demografie und Lifestyle-Faktoren (Geburtsdatum, Aktivitätslevel, Rauchstatus, Schlafstunden, BMI). Validiert, dass die Erwartung 40-120 Jahre beträgt und Schlaf 4-12 Stunden ist.
LifeStats: Deterministische Lebensstatistiken (Alter in Tagen, Gesamtwochen, aktueller Wochenindex, verbleibende Minuten). Erzwingt die Invariante, dass der aktuelle Wochenindex innerhalb der Gesamtwochen liegen muss – wenn du ein
LifeStatskonstruieren kannst, ist die Mathematik korrekt.Milestone: Ein Lebensereignis mit Label (max 50 Zeichen), Datum, Icon und Reihenfolge. Validiert, dass Labels nicht leer sind, Daten nicht in der Zukunft liegen und Reihenfolgewerte nicht-negativ sind für die Konfliktauflösung.
So funktioniert die Validierung in der Praxis:
@dataclass(frozen=True)
class Milestone:
label: str
date: date
icon_key: str
order: int = 0
def __post_init__(self):
if not self.label.strip():
raise DomainValidationError("Label required")
if self.date > date.today():
raise DomainValidationError("Milestone cannot be in future")
Wenn ein Milestone-Objekt existiert, ist es valide. Keine andere Schicht muss prüfen.
Vermeidung der Anemic Domain Model Falle
Ein häufiger Fehler ist, Entitäten als “Datenbeutel” ohne Verhalten zu behandeln – anemic domain models. Domain-Driven Design (DDD) lehrt uns, dass Kernobjekte ihre eigenen Invarianten schützen sollten. Unsere Profile-, LifeStats- und Milestone-Value-Objects sind nicht nur Datenstrukturen – sie erzwingen Business-Regeln durch __post_init__-Validierung. Wenn ein Milestone existiert, ist sein Datum valide, das Label nicht leer und es liegt nicht in der Zukunft. Die Domain-Schicht schützt sich selbst.
Wie Keen in Kapitel 4 feststellt, reduziert die Verwendung von Pythons @dataclass Boilerplate, während reichhaltige Domain-Models erstellt werden, die sowohl Daten als auch die Regeln, die diese Daten regieren, kapseln.
Das Policy-Pattern: Konfigurierbare Business-Regeln
Die ExpectancyPolicy kapselt alle Anpassungsregeln für die Lebenserwartung als konfigurierbare Deltas. Statt “hohe Aktivität addiert 2 Jahre” in einer Berechnung zu hardcodieren, speichern wir es als Daten in Dictionaries und aufrufbaren Funktionen:
activity_deltas: HIGH +2.0 Jahre, MODERATE 0.0, LOW -2.0smoking_deltas: HEAVY -8.0 Jahre, LIGHT -3.0, NONE 0.0sleep_delta: Optimaler Schlaf (6-9 Stunden) +0.5 Jahre, sonst -1.0bmi_delta: Gesundes BMI (18.5-25) +0.5 Jahre, fettleibig (≥30) -3.0
Die apply()-Methode der Policy summiert alle Deltas und begrenzt das Ergebnis auf 40-120 Jahre. Diese Trennung macht die Regeln explizit, isoliert testbar und leicht konfigurierbar. Möchtest du die Rauchstrafe anpassen? Ändere eine Zahl in der Policy, nicht verstreut im Berechnungscode.
@classmethod
def default(cls) -> "ExpectancyPolicy":
"""Factory: Standard-Policy mit evidenzbasierten Deltas."""
return cls(
activity_deltas={Activity.HIGH: 2.0, Activity.LOW: -2.0, ...},
smoking_deltas={Smoking.HEAVY: -8.0, Smoking.LIGHT: -3.0, ...},
sleep_delta=lambda hours: 0.5 if 6 <= hours <= 9 else -1.0,
bmi_delta=lambda bmi: 0.5 if 18.5 <= bmi < 25 else ...
)
Domain Services: Reine Business-Logik
Domain Services orchestrieren Value Objects und Policies ohne Seiteneffekte. Sie sind pure Functions – gleiche Eingabe produziert immer gleiche Ausgabe, keine versteckten Abhängigkeiten:
compute_expectancy(): Nimmt einProfileund eineExpectancyPolicy, gibt angepasste Jahre zurück. Keine Datenbankaufrufe, kein File I/O, nur Mathematik.resolve_milestones(): Mappt Meilenstein-Daten auf Wochenindizes im Lebensgitter und begrenzt Daten, die außerhalb der erwarteten Lebensspanne fallen. Wenn du einen Meilenstein für 2050 hinzufügst, aber dein Gitter nur bis 2045 geht, begrenzt es auf die letzte Woche und setztwas_clamped=True.compute_life_stats(): Berechnet bei gegebenem Geburtsdatum und Erwartung Gesamtwochen, aktuellen Wochenindex und verbleibende Minuten. Reine Berechnung, deterministische Ausgabe.
Die zentrale Erkenntnis: Diese Services können ohne Mocks, Datenbanken oder UI getestet werden. Übergib Value Objects, prüfe die Ausgabe. Kein Setup, kein Teardown, keine flaky Tests.
Application Layer: Der Orchestrator#
Diese Schicht koordiniert Domain-Logik durch Use Cases – beantwortet „was kann diese Anwendung tun?" ohne festzulegen „wie macht sie es?" Sie definiert drei Schlüsselkomponenten: DTOs für Datenvalidierung, Use Cases für Orchestrierung und Ports für Infrastructure-Verträge.
DTOs: Pydantic-Validierungsschicht
DTOs verwenden Pydantics Field-Validatoren, um ungültige Eingaben abzufangen, bevor sie die Domain erreichen. Zum Beispiel stellt ProfileDTO sicher, dass die Basis-Erwartung zwischen 40-120 Jahren liegt (Field(ge=40.0, le=120.0)), Schlafstunden 4-12 sind (Field(ge=4, le=12)) und Größe/Gewicht positiv sind (Field(gt=0)). Die Literals beschränken Aktivität auf “low”, “moderate” oder “high” – alles andere schlägt zur Parse-Zeit fehl.
Jedes DTO hat eine to_domain()-Methode, die validierte Eingaben zu Domain-Value-Objects konvertiert, String-Literals zu Enums mappt und Typumwandlungen handhabt. Diese saubere Grenze bedeutet, dass Domain-Objekte niemals ungültige Daten sehen.
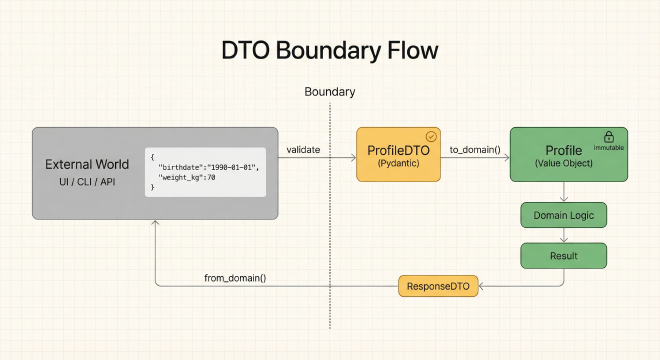
Wenn die Validierung fehlschlägt, liefert Pydantic aussagekräftige Fehlermeldungen: "baseline_expectancy: ensure this value is less than or equal to 120.0". Keine kryptischen Exceptions – Benutzer erhalten umsetzbares Feedback.
Use Cases: Die 10-Schritt-Orchestrierung
Der generate_poster_uc Use Case orchestriert den gesamten Poster-Generierungs-Workflow in 10 verschiedenen Schritten:
- Validiere Request — Pydantic DTOs fangen fehlerhafte Eingaben ab
- Konvertiere zu Domain — DTOs werden zu unveränderlichen Value Objects
- Berechne Erwartung — Wende Policy-Deltas auf Basis an
- Berechne Lebensstatistiken — Berechne Gesamtwochen, aktuellen Index
- Löse Meilensteine auf — Mappe Daten auf Wochenindizes
- Behandle Konflikte — Wenn mehrere Meilensteine auf dieselbe Woche fallen, nutze order-Feld
- Berechne Geburtstage — Spezielle Behandlung für 29. Feb Schaltjahr-Edge-Case
- Generiere Titel — Baue Titel/Untertitel aus Profil
- Wende Theme an — Starte mit Preset, wende Benutzer-Overrides an
- Rendere — Rufe PosterRenderer-Port auf (Dependency Inversion)
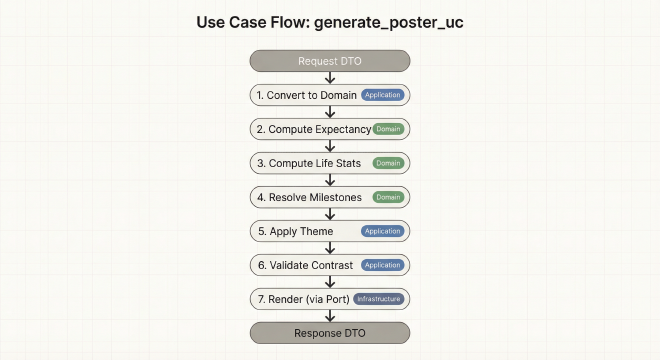
Jeder Schritt ist eine einzelne Verantwortung. Der Use Case koordiniert, implementiert aber nicht die Logik – die lebt in Domain Services. Wenn die Geburtstagsberechnung gefixt werden muss, ändere eine Domain-Funktion. Der Use Case bleibt unverändert.
Hier ist der Vertrag, von dem der Use Case abhängt:
class PosterRenderer(Protocol):
def render(
self,
stats: LifeStats,
milestones: list[ResolvedMilestone],
theme: VisualTreatment
) -> bytes:
"""Render poster to PNG bytes."""
...
Der Use Case weiß nichts über Pillow. Wir könnten SVG, PDF oder HTML Canvas einbinden, indem wir dieses Interface implementieren.
Ports: Infrastructure-Verträge
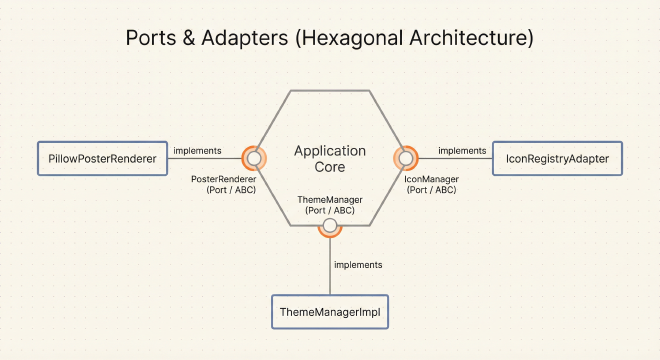
Die Application-Schicht definiert abstrakte Interfaces, die Infrastructure implementieren muss. Drei Schlüsselports:
PosterRenderer:
render()nimmt Lebensstatistiken, Meilensteine, Theme und gibt PNG-Bytes zurück. Die Application kümmert sich nicht darum, ob du Pillow, Cairo oder Playwright nutzt – implementiere einfach dieses Interface.IconManager:
get_icon_by_key()holt Icons nach Namen,get_curated_icons()gibt eine UI-freundliche Liste zurück. Ob Icons von Material Design, Font Awesome oder einer Datenbank kommen, ist Sache der Infrastructure.ThemeManager:
get_theme_preset()lädt retro/mono Themes,validate_theme_contrast()stellt WCAG AA-Compliance sicher. Die Validierungslogik lebt in Infrastructure, aber die Application erzwingt den Vertrag.
Zentrale Erkenntnis: Der Use Case weiß nichts über Pillow, Streamlit oder Material Design Icons. Er kennt nur die Verträge (Ports). Dies ist Dependency Inversion in Aktion – die innere Schicht besitzt das Interface, die äußere Schicht folgt ihm.
Warum Protocol statt ABC?
Pythons Protocol (eingeführt in PEP 544) ermöglicht strukturelles Subtyping – “Duck Typing mit statischen Garantien.” Im Gegensatz zu ABCs vererbungsbasiertem Ansatz lassen Protocols uns Verhalten definieren, ohne eine Vererbungshierarchie zu erzwingen. Wie Sam Keen in “Clean Architecture with Python” betont, passt dies besser zu Pythons dynamischer Natur, während architektonische Grenzen erhalten bleiben, die Tools wie mypy verifizieren können.
Der PillowPosterRenderer implementiert PosterRenderer, ohne von ihm zu erben – einfach durch eine passende render()-Signatur. Das ist Pythonic Dependency Inversion.
Infrastructure Layer: Die Adapter#
Hier leben die chaotischen Real-World-Details – Pillow-Rendering, Streamlit UI-Komponenten, CLI-Argument-Parsing, File I/O und das Theme-System. Diese Adapter implementieren die Verträge, die vom Application Layer definiert wurden.
Renderer: Spezialisierte Factories
Der PillowPosterRenderer nutzt das Factory-Pattern, um spezialisierte Konfigurationen ohne Code-Änderung zu erstellen:
for_print(): 300 DPI mit 4x Scale-Faktor für professionellen Druck. Dieselbe Grid-Berechnung, aber viel höhere Auflösung.for_large_lifespans(): Kleinere Zellen (8px statt 12px) mit reduziertem Font-Scale (0.8x) für Hundertjährige. Passt 100+ Jahre auf den Bildschirm ohne Scrollen.
Der Renderer berechnet das Layout dynamisch: 52 Spalten (Wochen pro Jahr), Zeilen = Gesamtwochen ÷ 52, plus einen Legendenbereich, dessen Höhe mit der Meilenstein-Anzahl skaliert. Icons werden mit automatischer kontrastbasierter Farbauswahl gerendert – wenn ein Icon auf seinem Hintergrund unsichtbar wäre (Kontrastverhältnis < 4.5:1), wechselt der Renderer zu Schwarz oder Weiß für maximale Sichtbarkeit.
Das ist WCAG AA-Compliance (4.5:1 für normalen Text), die zur Render-Zeit passiert, nicht als Nachgedanke.
Adapters: Brücke zwischen Infrastructure und Ports
Infrastructure-Komponenten sind in Adapter gewrappt, die Application-Ports implementieren. Der IconRegistryAdapter ist ein perfektes Beispiel: Er wrappt die konkrete IconRegistry (die über Material Design Icon-Dateien, Unicode-Zeichen, SVG-Pfade Bescheid weiß) und exponiert nur das IconManager-Interface, das die Application erwartet.
Dieses Adapter-Pattern ist die Brücke zwischen “wie Icons tatsächlich funktionieren” (Infrastructure-Detail) und “was Icons tun” (Application-Vertrag). Möchtest du von Material Design zu Font Awesome wechseln? Schreibe einen neuen Adapter. Die Application-Schicht merkt den Unterschied nie.
Material Design Icons & WCAG-Compliance
Die Icon-Registry enthält 12+ Material Design Icons (school, work, home, favorite, flight, cake, etc.) mit automatischer kontrastbasierter Farbauswahl. Beim Rendern eines Icons auf einem farbigen Hintergrund analysiert der Renderer das Kontrastverhältnis:
def _select_icon_color(self, background_color: str, theme: VisualTreatment) -> str:
"""Wähle Icon-Farbe mit WCAG AA Kontrast-Garantie (4.5:1)."""
bg_luminance = calculate_luminance(background_color)
# Versuche zuerst Theme-Icon-Farbe
if contrast_ratio(bg_luminance, calculate_luminance(theme.icon_color)) >= 4.5:
return theme.icon_color
# Fallback: Wähle Schwarz oder Weiß für maximalen Kontrast
return "#000000" if bg_luminance > 0.5 else "#FFFFFF"
WCAG AA erfordert ein 4.5:1 Kontrastverhältnis für normalen Text. Das Theme-System validiert dies in Echtzeit und warnt Nutzer, wenn ihre Custom-Farben schlechte Barrierefreiheit riskieren.
CLI: Von Argumenten zu Use Cases
Der CLI-Adapter parst Command-Line-Argumente und konvertiert sie zu DTOs, die Use Cases verstehen. Meilensteine kommen als "Graduated|2012-06-15|school" Strings herein, werden gesplittet und validiert, dann in MilestoneDTO-Objekte verpackt. Die zentrale Erkenntnis: CLI, Streamlit UI und eine zukünftige REST API erstellen alle dasselbe GeneratePosterRequest DTO und rufen denselben generate_poster_uc Use Case auf. Null Logik-Duplikation – nur verschiedene Wege, die Request zu bauen.
Die Kraft der Trennung: Was Wir Gewonnen Haben#
Testbarkeit#
Die CS50-Version hatte 25 Tests – alles Integrationstests, wo das Testen der Geburtstags-Logik bedeutete, Rendering, Fonts und File I/O aufzusetzen. Die refaktorierte Version hat 303 Tests in vier Kategorien organisiert, jede mit einem spezifischen Zweck.
Unit-Tests: Isolierte Domain-Logik
Domain-Layer-Tests sind rein – keine Mocks, keine Datenbanken, kein Rendering. Sie testen Business-Logik in vollständiger Isolation. Zum Beispiel erfordert das Testen, dass hohe Aktivität 2 Jahre zur Erwartung addiert, nur ein Profile-Objekt und eine ExpectancyPolicy. Kein Pillow-Setup, kein File I/O, nur reine Mathematik. Testen, dass Meilensteine nicht in der Zukunft liegen können? Versuche einen mit morgigem Datum zu erstellen und prüfe, dass er DomainValidationError wirft. Schnell, deterministisch, keine flaky Failures.
Integrationstests: End-to-End-Workflows
Integrationstests verifizieren die gesamte Poster-Generierungs-Pipeline von Request DTO zu PNG-Bytes. Der herausragende ist test_wysiwyg (What You See Is What You Get) – er verifiziert, dass Streamlits Vorschau den exakt gleichen generate_poster_uc Use Case und Renderer wie Export nutzt. Preview-Bytes müssen Export-Bytes Pixel-für-Pixel entsprechen. Dieser Test hat einen Bug gefangen, bei dem die Vorschau das Standard-Theme nutzte, während Export die Benutzerauswahl respektierte.
Architektur-Tests: Fitness Functions
Keen nennt diese Fitness Functions – automatisierte Verifikation, dass die Architektur intakt bleibt, während sich der Code entwickelt. Diese Tests erzwingen die Dependency Rule und fangen Verletzungen ab, bevor sie den Codebase verrotten lassen.
Diese Tests nutzen Pythons Abstract Syntax Tree (AST), um Imports statisch zu analysieren und Layer-Grenzen durchzusetzen:
# test_layer_boundaries.py
def test_domain_has_zero_external_dependencies():
"""Domain-Layer darf nur stdlib importieren (kein Pillow, Pydantic, etc.)."""
domain_files = get_python_files("domain/")
for file in domain_files:
tree = ast.parse(file.read_text())
imports = extract_imports(tree)
# Domain darf nur importieren: stdlib, typing, dataclasses, abc
allowed_prefixes = ("typing", "dataclasses", "abc", "datetime", "enum")
external_imports = [
imp for imp in imports
if not imp.startswith(allowed_prefixes)
and not imp.startswith("domain")
]
assert not external_imports, (
f"{file.name} importiert externe Abhängigkeiten: {external_imports}"
)
# test_module_sizes.py
def test_modules_under_size_limit():
"""Setze Code-Größen-Limits durch, um God Objects zu verhindern."""
SOFT_LIMIT = 400 # Warn-Schwelle
HARD_LIMIT = 600 # Hard-Failure-Schwelle
for module in get_python_files():
line_count = count_loc(module)
assert line_count < HARD_LIMIT, (
f"{module.name} hat {line_count} LOC (Limit: {HARD_LIMIT})"
)
if line_count > SOFT_LIMIT:
warnings.warn(f"{module.name} ist groß ({line_count} LOC)")
# test_dependency_direction.py
def test_no_circular_dependencies():
"""Erkenne zirkuläre Imports zwischen Modulen."""
graph = build_dependency_graph()
cycles = detect_cycles(graph)
assert not cycles, f"Zirkuläre Abhängigkeiten erkannt: {cycles}"
Contract-Tests: Interface-Validierung
Contract-Tests verifizieren, dass Themes und Icons ihre Verträge erfüllen. test_all_theme_presets_meet_wcag_aa berechnet das Kontrastverhältnis zwischen Text/Icons und Hintergründen für beide “retro” und “mono” Themes und stellt sicher, dass alle 4.5:1 (WCAG AA-Minimum) überschreiten. test_all_icons_have_required_fields verifiziert, dass jedes kuratierte Icon einen gültigen Schlüssel (Python-Identifier), einen Display-Namen und entweder ein Unicode-Zeichen oder SVG-Pfaddaten hat – sicherstellt, dass Icons tatsächlich renderbar sind.
Die Test-Pyramide: 60% Unit-Tests (schnell, isoliert), 25% Integrationstests (langsamer, umfassend), 10% Architektur-Tests (CI-Durchsetzung), 5% Contract-Tests (Interface-Validierung). Architektur-Tests sind die Geheimwaffe – sie verhindern architektonischen Verfall automatisch.
Erweiterbarkeit#
Neue Features erfordern kein Umschreiben existierenden Codes mehr. Themes gewünscht? Implementiere den ThemeManager-Port. PDF-Output? Schreib einen anderen PosterRenderer. Mobile App? Nutze dieselben Use Cases. Die CLI- und Streamlit-Versionen demonstrieren dies perfekt – dieselbe Business-Logik, verschiedene Interfaces:
# CLI-Version
def cli_main():
request = build_request_from_args()
renderer = PillowPosterRenderer()
response = generate_poster_uc(request, renderer)
save_image(response.image_data)
# Streamlit-Version
def streamlit_main():
request = build_request_from_form()
renderer = PillowPosterRenderer()
response = generate_poster_uc(request, renderer)
st.download_button("Download", response.image_data)
Keine Duplikation. Nur verschiedene Wege, dieselbe Orchestrierung aufzurufen.
Wartbarkeit#
Im Monolithen konnte das Ändern der Geburtstags-Logik Rendering, UI und Tests brechen – jede Änderung hatte unvorhersehbare Auswirkungen. Mit Clean Architecture erfordert das Ändern der Geburtstags-Logik nur das Update der Domain-Tests. Alles andere funktioniert weiter, weil Änderungen innerhalb ihrer Schicht bleiben.
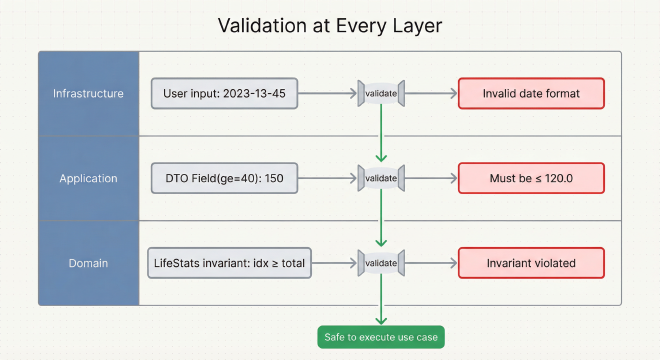
Validierung auf Jeder Schicht#
Eine der Stärken von Clean Architecture ist Defense in Depth: Jede Schicht validiert Daten auf ihrem angemessenen Level, fängt Fehler früh ab und liefert aussagekräftiges Feedback.
Domain-Validierung: Business-Invarianten
Die Domain-Schicht erzwingt Business-Invarianten durch unveränderliche Dataclasses mit __post_init__-Validierung. Zum Beispiel prüft LifeStats, dass der aktuelle Wochenindex innerhalb der Gesamtwochen liegt – eine mathematische Invariante, die immer gelten muss. Wenn age_days oder minutes_remaining negativ sind, wirft es DomainValidationError. Domain-Validierung geht um Business-Regeln, die definieren, was “valide” für deine Kernkonzepte bedeutet.
Application-Validierung: Eingabe-Constraints
Die Application-Schicht nutzt Pydantic, um externe Eingaben zu validieren, bevor sie die Domain erreichen. DTOs definieren Constraints mit Field-Validatoren: baseline_expectancy: float = Field(ge=40.0, le=120.0) bedeutet, dass die Application nicht einmal versucht, ein Domain-Objekt zu erstellen, wenn die Erwartung 150 Jahre beträgt. Wenn die Validierung fehlschlägt, liefert Pydantic aussagekräftige Fehlermeldungen: "ensure this value is less than or equal to 120.0". Keine kryptischen Exceptions – Benutzer erhalten umsetzbares Feedback mit Feldnamen und Constraints.
Infrastructure-Validierung: Benutzer-Eingabe-Sanitization
Die Infrastructure-Schicht behandelt UI-Level-Validierung – Parsing von Daten aus Strings, Sanitization von Benutzereingaben, Prävention von Injection. Die CLI parst Meilenstein-Argumente als "Label|YYYY-MM-DD|icon_key" Strings und validiert das Format, bevor DTOs erstellt werden. Wenn der Datumsstring fehlerhaft ist, erhältst du "Invalid date format: 2023-13-45 (expected YYYY-MM-DD)" sofort, nicht einen Stack-Trace tief in der Domain-Logik.
Fehler-Flow
Fehler steigen mit Kontext auf jeder Schicht:
Infrastructure: Parse "2023-13-45" → Error: "Invalid date format"
Application: Field(ge=40) validates 150 → Error: "Must be ≤ 120.0"
Domain: LifeStats checks 0 ≤ idx < total → Error: "Invariant violated"
Diese Multi-Layer-Strategie fängt Fehler auf der richtigen Ebene ab und macht Debugging unkompliziert.
Neue Features durch Architektur Ermöglicht#
Sobald die Schichten getrennt waren, wurde das Hinzufügen von Features unkompliziert. Die Architektur machte drei große Erweiterungen möglich.
Meilenstein-System#
Du kannst jetzt unbegrenzt Meilensteine mit Custom Icons hinzufügen – Abschlüsse, Hochzeiten, Karrierewechsel, Geburten. Das Meilenstein-System demonstriert Clean Architectures Macht: Domain-Validierung, Application-Orchestrierung und Infrastructure-Rendering arbeiten nahtlos zusammen.
Konfliktauflösung
Wenn mehrere Meilensteine auf dieselbe Woche fallen, gruppiert das System sie nach Wochenindex und behält nur den Meilenstein mit der höchsten Reihenfolge aus jeder Gruppe. Das order-Feld bestimmt die Priorität – order 2 gewinnt über order 1, wenn beide auf Woche 1.234 landen. Diese einfache Regel verhindert visuelles Durcheinander, wo Icons sich überlappen würden.
CRUD-Operationen
Der Meilenstein-Service bietet create_milestone_list(), add_milestone_to_list(), remove_milestone_from_list() und reorder_milestone_in_list(). Jede gibt eine neue unveränderliche Liste zurück – funktionale Programmierung. Die Streamlit UI nutzt diese, um Meilensteine mit ⬆️/⬇️ Buttons neu zu ordnen oder mit 🗑️ zu löschen.
ResolvedMilestone: Die Brücke
ResolvedMilestone mappt einen Milestone (Domain-Konzept mit Datum) auf einen spezifischen week_index (Rendering-Koordinate). Wenn du einen Meilenstein für 2050 hinzufügst, aber dein Gitter nur bis 2045 reicht, begrenzt es auf die letzte Woche und setzt was_clamped=True. Dieses Flag lässt die UI Benutzer warnen: “Dieser Meilenstein erstreckt sich über deine erwartete Lebensspanne hinaus.”
Material Design Icons
Die Infrastructure liefert 12+ kuratierte Material Design Icons, organisiert nach Kategorie: Bildung (school, menu_book), Karriere (work, business_center), Persönliches (favorite, cake), Orte (home, location_on), Erfahrungen (flight, auto_awesome) und Verschiedenes (fitness_center, star). Jedes Icon wird mit automatischer kontrastbasierter Farbauswahl gerendert – wenn ein Icon auf seinem Hintergrund unsichtbar wäre, wechselt der Renderer zu Schwarz oder Weiß für WCAG AA-Compliance.
Theme-System#
Das Theme-System nutzt einen Token-basierten Ansatz mit zwei eingebauten Presets und vollständiger Anpassungsfähigkeit. Themes werden in Echtzeit auf Barrierefreiheits-Compliance validiert.
Theme-Tokens
Ein VisualTreatment Value Object definiert die komplette visuelle Palette: Hintergrundfarbe, Textfarbe, Grid-Linienfarbe, drei Wochen-Füllfarben (Vergangenheit/Aktuell/Zukunft), Geburtstags-Tönung, Icon-Farbe, Grid-Linien-Dicke und Icon-Scale. Das sind 9 anpassbare Parameter. Das “retro”-Theme nutzt warme Brauntöne und Cremes (#F5E6D3 Hintergrund, #8B7355 vergangene Wochen, #D4A574 aktuelle Woche). Das “mono”-Theme nutzt reine Graustufen (#FFFFFF Hintergrund, #9E9E9E vergangene Wochen, #616161 aktuelle Woche), optimiert für hochkontrastigen Druck.
Override-Mechanismus
Starte mit einem Preset, überschreibe spezifische Tokens. Möchtest du retro-Farben, aber mit reinem weißem Hintergrund? Lade “retro”-Preset, überschreibe background: "#FFFFFF". Der Theme-Manager wendet deine Overrides an und validiert Kontrastverhältnisse. Wenn das Text-auf-Hintergrund-Kontrast unter 4.5:1 (WCAG AA-Minimum) fällt, warnt die UI dich sofort: “Text auf Hintergrund hat niedrigen Kontrast (3.2:1)”. Die Validierung nutzt Luminanz-basierte Kontrastberechnung, dieselbe Formel, die Barrierefreiheits-Auditoren nutzen.
Die Streamlit UI zeigt diese Warnungen an, während du Farben anpasst, und verhindert, dass Benutzer unzugängliche Poster erstellen. Du kannst die Warnungen trotzdem überschreiben (dein Poster, deine Wahl), aber du triffst eine informierte Entscheidung.
Streamlit Web UI#
Die größte Erweiterung ist ein vollständiges Web-Interface, das komplett auf existierenden Use Cases aufbaut – formularbasierte Eingabe mit Validierung, Live-Vorschau, Meilenstein-Management, Theme-Anpassung mit Color Pickern, Echtzeit-Statistiken und Ein-Klick-Download. Weil die Business-Logik bereits in wiederverwendbaren Use Cases lebte, war das Bauen der Streamlit UI hauptsächlich das Verdrahten von Formularfeldern mit Funktionsaufrufen.
Die Streamlit UI ist eine Implementierung des Humble Object Pattern – bewusst logikfrei gehalten, damit sie “zu bescheiden ist, um zu brechen.” Alle Formatierung, Validierung und Business-Logik lebt in DTOs, Use Cases und Domain Services. Die UI zeigt nur an und erfasst Eingaben. Das macht die View selbst nahezu untestbar und unnötig zu testen – die testbare Logik liegt woanders.
Die UI führt dich Schritt für Schritt durch den Poster-Erstellungsprozess. Lass mich dir zeigen, wie es fließt:
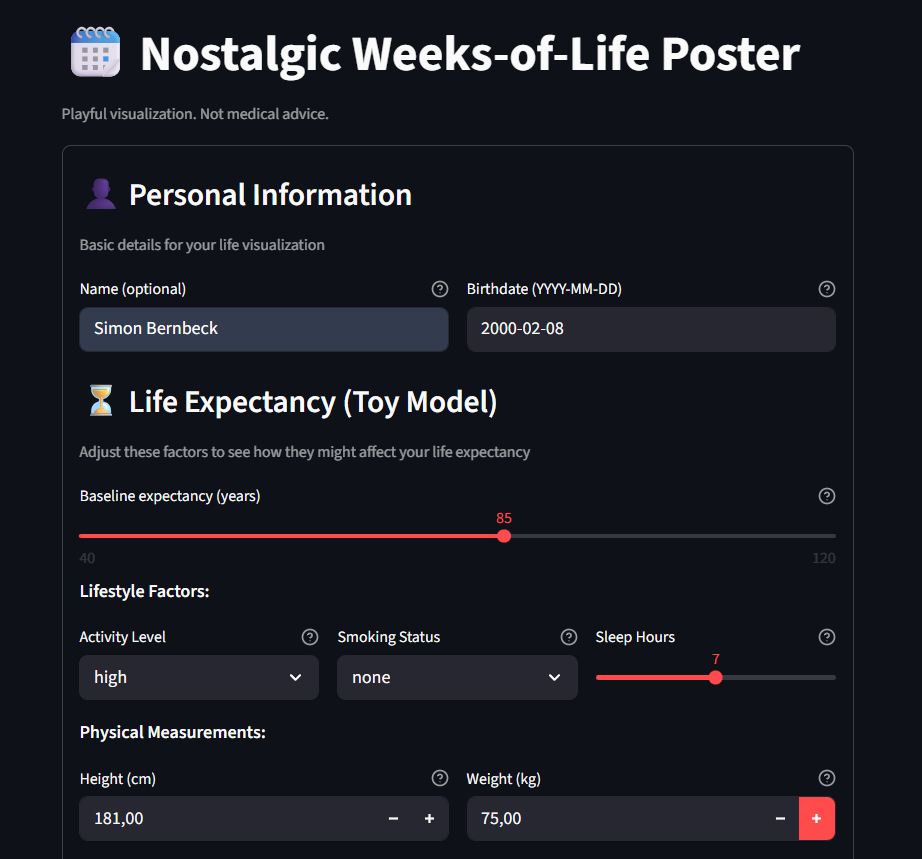
Du beginnst mit der Eingabe deines Namens (optional), Geburtsdatums (der Anker für das gesamte Gitter) und Basis-Lebenserwartung. Dann passt du Lifestyle-Faktoren an – Aktivitätslevel, Rauchstatus, Schlafstunden – und physische Messungen (Größe und Gewicht für BMI). Es ist bewusst ein Toy-Modell für Visualisierung, keine medizinische Beratung, aber es gibt dem Gitter etwas zum Arbeiten.
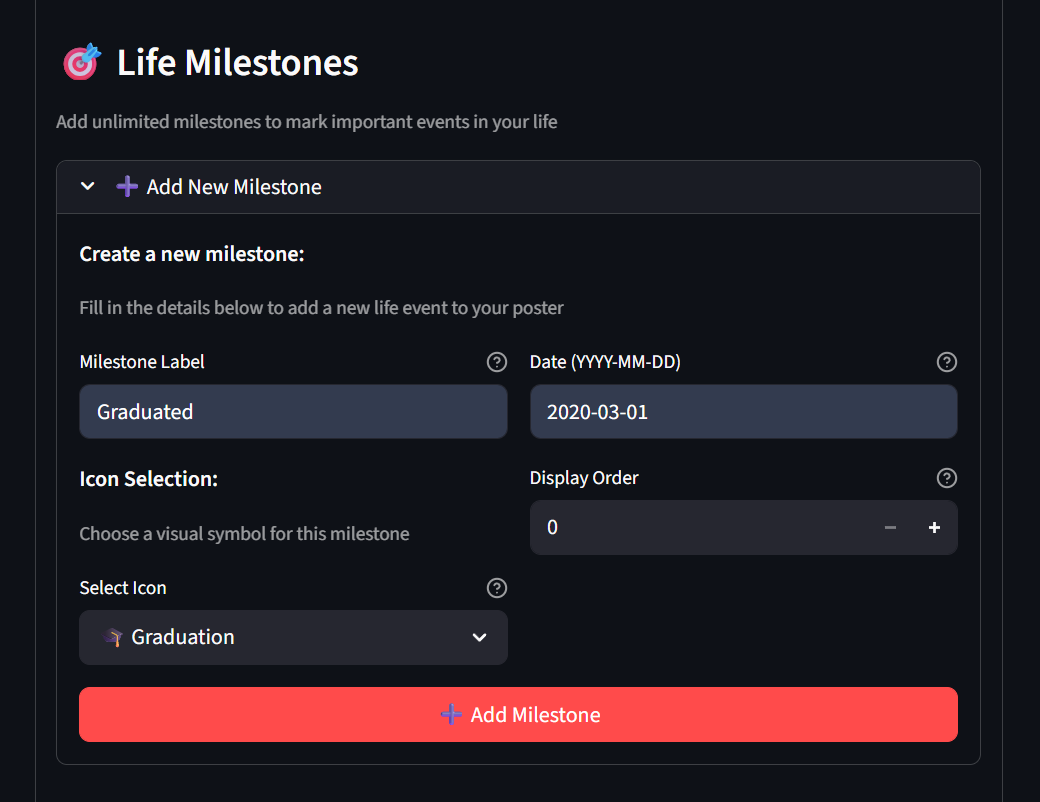
Als Nächstes fügst du Meilensteine hinzu: Abschlüsse, Karrierewechsel, Geburten. Jeder erhält ein Label, Datum, Icon und Display-Reihenfolge (für wenn mehrere Ereignisse auf dieselbe Woche fallen). Der Meilenstein-Manager lässt dich sie neu ordnen oder löschen, während du iterierst.
Der Theme-Selektor bietet „retro" (warme Vintage-Farben) oder „mono" (Graustufen, sicherer fürs Drucken), mit optionalen Überschreibungen für Poster-Titel und Untertitel.
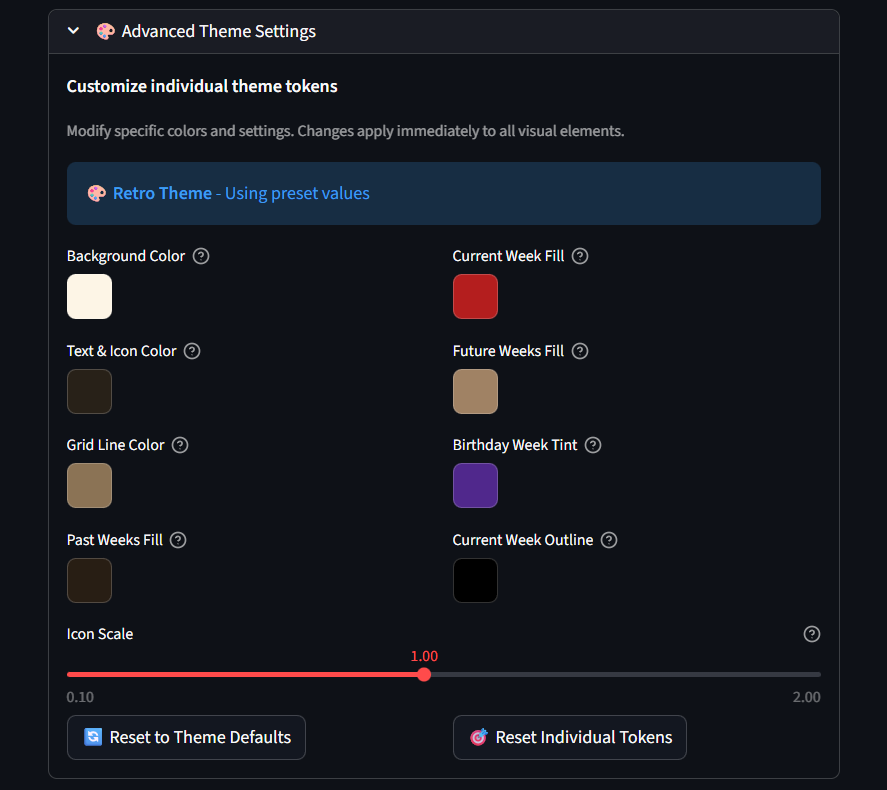
Für tiefere Anpassung lassen dich Advanced Theme Settings Hintergrundfarben, Grid-Linien, Wochen-Füllungen, Geburtstags-Tints, Textfarben und Icon-Scale fein justieren. Die UI warnt dich, falls deine Kombinationen niedrigen Kontrast riskieren, und du kannst jederzeit zu Defaults zurücksetzen.
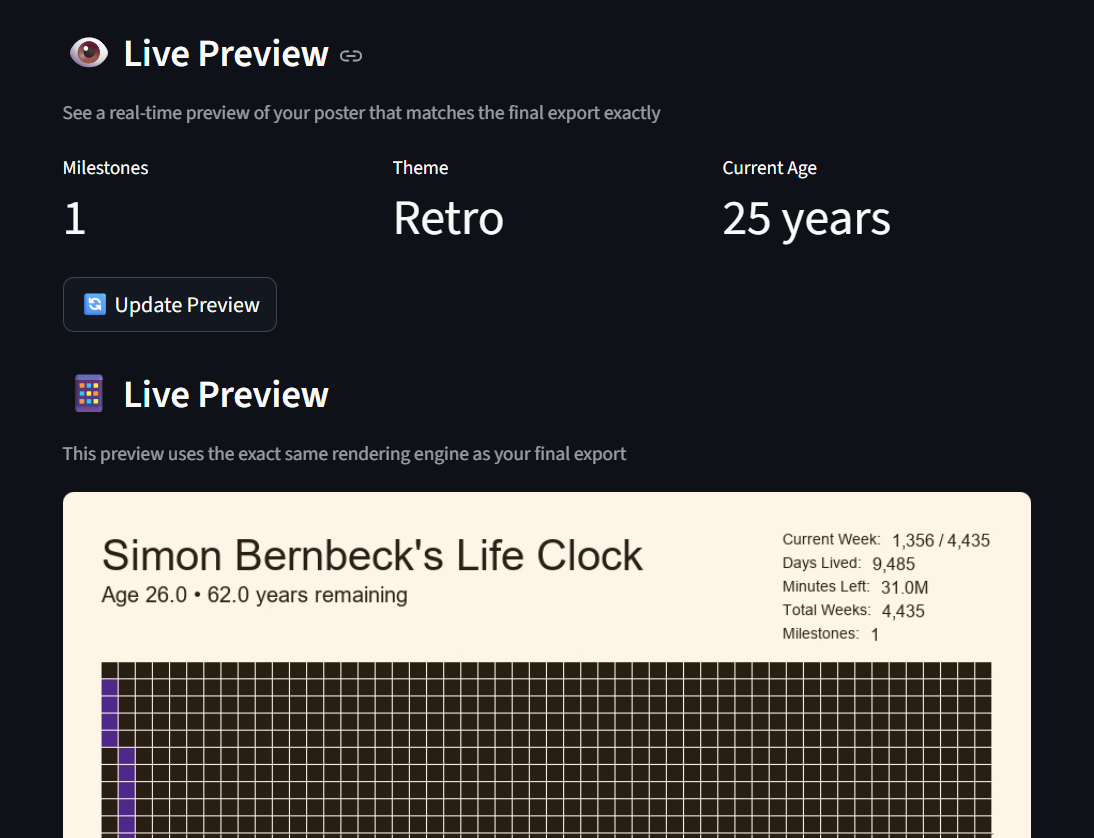
Die Live-Vorschau ist das Killer-Feature – sie nutzt denselben generate_poster_uc Use Case und Pillow Renderer wie der finale Export, sodass du siehst, was du bekommst. Du siehst Metriken (Meilenstein-Anzahl, aktuelles Alter, Theme), dann klickst du „Update Preview" zum Regenerieren.
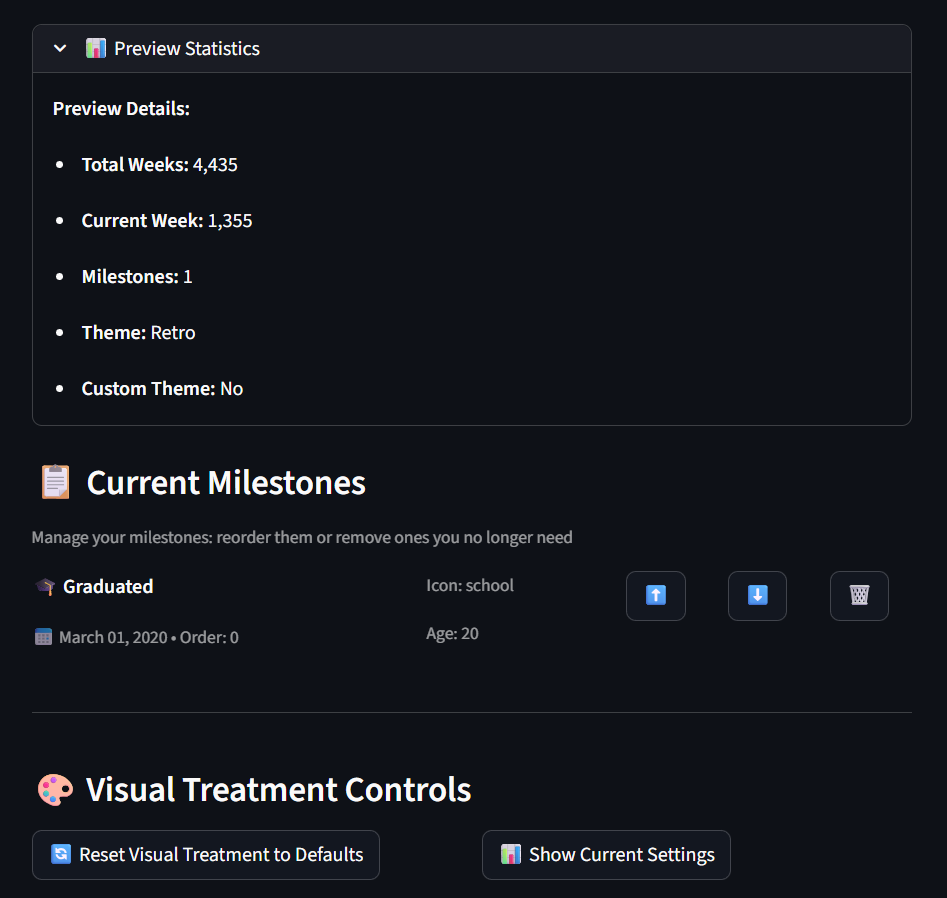
Schließlich zeigt das Vorschau-Statistik-Panel Gesamt-Wochen, aktuellen Wochen-Index, Meilenstein-Anzahl und ob du ein Custom Theme nutzt. Der Meilenstein-Manager lässt dich Ereignisse neu ordnen (⬆️/⬇️) oder löschen (🗑️), und die Visual Treatment Controls lassen dich deine Einstellungen zurücksetzen oder einen Snapshot machen.
Das Ergebnis: Jeder kann ein Poster generieren, ohne Command-Line-Kenntnisse. Und falls du professionelle physische Ausgabe brauchst, generiert der Print-Modus (PillowPosterRenderer.for_print()) 300 DPI-Bilder, die du rahmen und aufhängen kannst.
Gelernte Lektionen#
Rückblickend leiteten vier Prinzipien das Refactoring:
Starte einfach, refaktoriere, wenn Schmerz auftritt. Ich baute keine Clean Architecture für CS50 – ich baute das einfachste Ding, das funktionierte. Erst als ich Meilensteine und Themes hinzufügen wollte, wurde der Schmerz des Monolithen klar. Das ist der richtige Zeitpunkt zum Refactoring. Über-Architektiere nicht von Anfang an.
Architektur geht um Grenzen. Clean Architecture geht nicht um Perfektion; es geht darum, klare Linien zu ziehen, sodass Änderungen in einem Bereich nicht überall hin ausstrahlen. Selbst unvollkommene Grenzen sind besser als keine.
Tests sind dein Sicherheitsnetz. Diese 303 Tests ließen mich furchtlos refaktorieren. Wenn du alles umstrukturierst, sind Tests der einzige Beweis, dass deine Logik noch funktioniert. Ich hätte dieses Refactoring nicht ohne sie machen können.
Die Dependency Rule ist nicht verhandelbar. Domain weiß nichts über Infrastructure. Brich diese Regel einmal und du bist zurück beim Monolithen. Architektur-Tests setzen dies automatisch durch, sodass die Disziplin mechanisch wird.
Probier es Selbst Aus#
Repository: Sims2k/lifeclock_cleanarch
Schnellstart:
# Klonen und installieren
git clone https://github.com/Sims2k/lifeclock_cleanarch
cd lifeclock_cleanarch
uv sync # oder: pip install -r requirements.txt
# Streamlit UI starten
streamlit run infrastructure/ui_streamlit.py
# CLI ausführen
python project.py --birthdate 1990-01-01 --height-cm 175 --weight-kg 70
Die infrastructure/ui_streamlit.py und project.py dienen als Composition Roots – die einzigen Orte, an denen Clean Architectures Trennung bewusst verletzt wird, um Abhängigkeiten zusammenzuführen. Hier werden abstrakte Ports wie PosterRenderer ihren konkreten Implementierungen wie PillowPosterRenderer zugewiesen.
Vergleich mit der Original-CS50-Version: Sims2k/LifeClock
Architektur als Handwerk#
Die CS50-Version funktionierte. Die Clean Architecture-Version hält. Ich kann Features ohne Angst hinzufügen, Implementierungen ohne Umschreiben austauschen und den Code Monate später verstehen. Clean Architecture ist kein Overhead – es ist Investition in dein zukünftiges Ich.
Dein 200-Zeilen-Script braucht es vielleicht nicht. Aber wenn dieses Script zu 2.000 Zeilen mit Nutzern wächst, die darauf angewiesen sind, wirst du wünschen, du hättest diese Grenzen früher gezogen. Der Schmerz des Refactorings lehrt dich, wo diese Grenzen sein sollten.
Beide Versionen visualisieren dasselbe Life-Grid. Aber eine ist gebaut zum Evolvieren. Die Stoiker lehrten uns, uns auf Veränderung vorzubereiten. Clean Architecture ist, wie wir unseren Code darauf vorbereiten.
Ressourcen:
- Original LifeClock CS50 Artikel
- Clean Architecture with Python von Sam Keen – grundlegende Referenz für SOLID-Prinzipien, DDD-Patterns und typverstärktes Python in dieser Architektur
- Clean Architecture von Robert C. Martin – die ursprüngliche Clean Architecture-Methodik
- lifeclock_cleanarch Repository
- Streamlit Documentation
Dieser Artikel ist Teil meiner Digital Odyssey Serie, die die Evolution technischer Projekte dokumentiert. LifeClock begann als CS50 Python-Projekt und entwickelte sich zu einer Lektion in nachhaltigem Software-Design.